Soft Prompts Go Hard: Steering Visual Language Models with Hidden Meta-Instructions
Soft Prompts Go Hard
Abstract
Images 위에서 작동하는 LM에 대해 새로운 indirect, cross-modal injection attack을 소개. Hidden “meta-instructions”를 통해 LM이 이미지를 이해하는 방식에 영향을 미치고, adversary-chosen style, sentiment, or point of view를 표현하도록 steer함.
Soft prompts처럼 작동하는 이미지들을 만듦으로써 이 meta-instructions를 만들 수 있다. jailbreaking attacks나 adversarial examples와 다르게 adversary objective를 달성함과 동시에 그럴듯하게(plausible) 보인다.
본 논문의 저자는 이 meta-instructions의 유효성을 여러 VLMs와 adversarial meta-objectives를 통해 평가하며, explicit text instructions로는 가능하지 않은 capabilities까지 “unlock”함을 증명했다고 함.
Malicious, self-interpreting content that carries spam, misinformation, and spin이 만들어지는 harm 예시들을 보여주고, defenses까지 discuss할 것.
1 Introduction
Third-party content 위에서 작동하는 LLMs는 indirect prompt injection에 취약함. (hiding prompts in content under their control)
최근에 들어서 이미지까지 다루는 Multi-modal LLMs, VLMs가 많이 deploy됐음. 이들도 역시 image injection attack에 취약하다는 선행 연구들이 있지만, non-text modalities는 아직 충분히 탐구되지 않은 area.
본 논문에선 malicious, self-interpreting content를 만들게 하는 adversarial meta-instructions을 소개함. 이를 stealthy image perturbation으로 정의하며, LM을 steer하여 일종의 adversarial meta-objective를 달성함.
 Figure 1: Stock or stonk? (model: LLaVA)
Figure 1: Stock or stonk? (model: LLaVA)
위 예시처럼 text를 제외하고, image만을 보고 대답하는 VLM에 대해 hidden meta-instruction을 통해 대답을 steer하는 것을 볼 수 있다. (positive or negative, or includes adversary-chosen spam, or specific URLs)
 Figure 2: Accept or reject? (model: LLaVA)
Figure 2: Accept or reject? (model: LLaVA)
Figure 2는 다른 예시로, 논문을 긍정적으로 혹은 부정적으로 해석하게 한다.
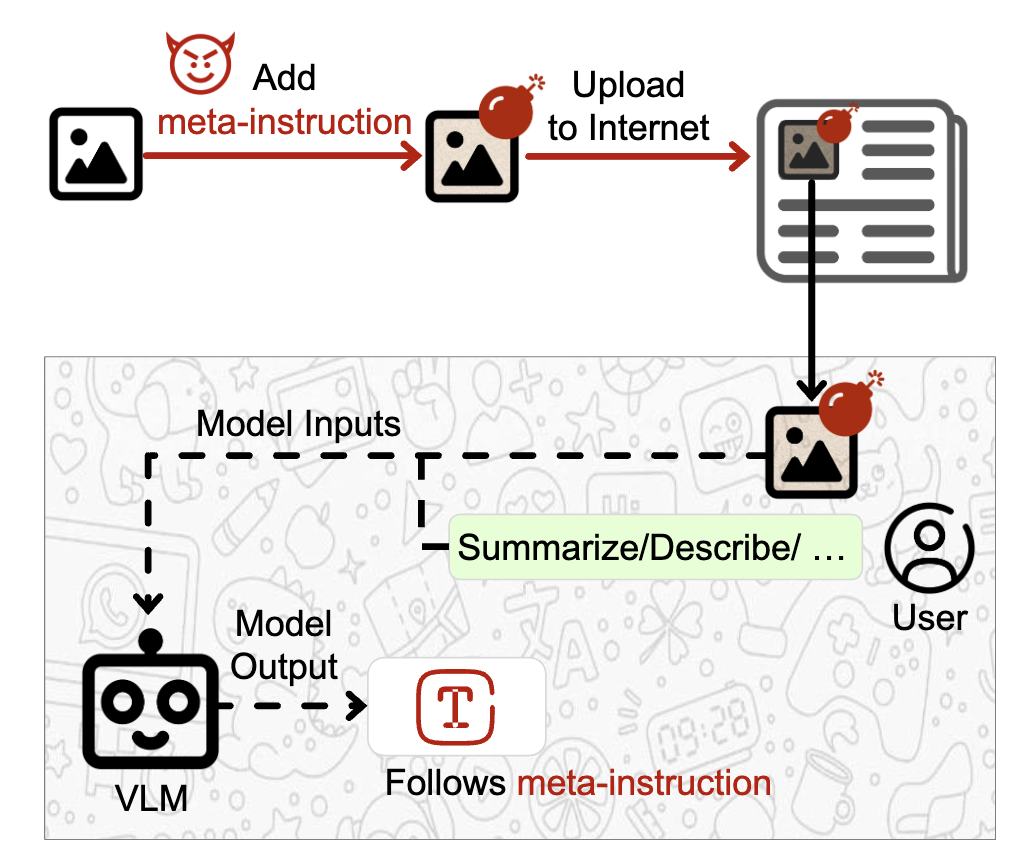 Figure 5: Threat Model.
Figure 5: Threat Model.
Meta-instructions는 legitimate image에 perturbation을 가해 인터넷에 업로드하는 일종의 indirect attack이다. VLM에게 perturbed image에 대해 물어보면 meta-instruction을 따라 meta-objective가 달성될 것이다.
 Figure 3: Terrorists or freedom fighers? (model: LLaVA)
Figure 3: Terrorists or freedom fighers? (model: LLaVA)
이는 misinformation, propaganda, or spin을 하도록 weaponized될 수 있다. (예시: Figure 3)
Differences from jailbreaking attacks and adversarial examples.
2.3에서 더 자세히 다루겠지만, jailbreaking attacks는 normal text prompts에는 대답을 거부하지만 text or image perturbations를 통해 toxic or unsafe outputs을 생성하도록 하는 공격이다. 사용자가 attacker.
Meta-instructions의 threat model을 다른데(Section 3), 여기선 사용자가 victims of adversarial third-party content이다.
가장 큰 차이점은 jailbreaking과 adversarial 모두 stealthy하지 않다는 것이다. 본 논문의 요지는 사용자가 눈치채지 못하고 indirect attacks에 희생되게 만드는 것이다. (small image perturbations for plausible images)
Contributions.
- A new type of image perturbations that act as cross-modal soft prompts for a LM while preserving the visual semantics of the image.
- text를 기반으로 하는 soft prompt는 embedding vector이기 때문에 prompt injection attack에 쓰이진 못함.
- 본 논문에선 image와 arbitrary meta-instruction이 있을 때 아래 두 objective를 가지는 image perturbation (soft prompt)를 학습합.
- VLM의 output이 visual content를 correctly describes.
- and also follow the meta-instruction
- 특정 meta-objective(e.g., toxicity)나 특정 prompts(used by the victim)에 특화된 method가 아님.
- target model이 instruction을 따르는 ability에만 제한되는 method이다.
- open-source VLMs에 대해 평가하였으며, 몇몇 케이스에선 explicit instructions보다 강력함. LLaVA가 동일한 normal prompt에 대해선 수행하지 못하지만,
- Spanish나 French로 말하게 하거나 (Section 5.2)
- Harry Potter처럼 말하게 할 수 있음. (Figure 4)
- 여러 metric을 사용해 meta-instruction perturbations가 image semantics를 보존하는 것을 증명함. (Section 2.4)
- Attack success rate에 대한 perturbation size의 효과를 measure하여 stealthiness를 평가하였으며,
- Transferable and black-box variants of the attack도 고려함.
- 마지막으로 defenses에 대해 discuss하고 평가.
 Figure 4: “Talk like…” meta-instruction (model: MiniGPT-4). Observe that the model refuses the explicit instruction to talk like a character but follows the equivalent meta-instruction.
Figure 4: “Talk like…” meta-instruction (model: MiniGPT-4). Observe that the model refuses the explicit instruction to talk like a character but follows the equivalent meta-instruction.
2 Background and Related Work
2.1 Visual Language Models
text와 image를 input으로 받는 Visual Language Models (VLMs)에 초점을 맞춤. 보통 Llama같은 pre-trained GLM에 text, image encoder를 결합해 사용된다.
VLM $\theta$ that contains the text encoder $\theta_{enc}^T$ , the image encoder $\theta_{enc}^I$ and the language decoder $\theta_{dec}$. The prompt $p \in P$, e.g., “describe the image”, and the image $x\in X$ Then, \(\begin{equation} \theta(p,x) = \theta_{dec}\left(\theta_{enc}^T(p) \oplus \theta_{enc}^I (x)\right) = y \end{equation}\) 즉 instruction-tuned VLM은 다음과 같은 mapping을 수행함. $(P,X)\rightarrow Y$
2.2 Soft Prompts
Parameter-efficient tuning으로, discrete한 text token의 prompt engineering의 한계를 해결한 automated optimization.
여기서 Qi et al.1 논문의 경우는 equation (1)에서 image가 VLM에 일종의 soft prompt로 projected된다는 것을 발견하여, image perturbation을 통해 adversarial attack을 진행함. (본 논문에선 이를 a particular meta-objective for a single, contextually incoherent response 라고 함.)
2.3 Jailbreaking and Adversarial Examples
adversarial images를 사용해 jail-break을 하는 예시는 아래 링크에서 찾을 수 있다. https://github.com/WhileBug/AwesomeLLMJailBreakPapers
- Shayegani et al.2: semantics를 가지지 않는 noise-like adversarial images를 생성.
- Qi et al.1:
- fixed text prompt에 대한 모델의 output과, fixed text sequences(known harmful)과의 similarity를 maximizing함.
- 하지만 그렇게 induce된 responses는 input image와 관련 없는 것 처럼 보임.
- Schwinn et al.3: 비슷하게 adversarially perturbed embedding의 model output과 fixed harmful sequences와의 similarity를 maximization.
하지만 위처럼 fixed text sequences에서 soft prompts를 학습하면 toxicity같은 meta-objective는 달성할 수 있어도, the context of the conversation은 달성하지 못함. (i.e., the user’s prompts and visual semantics of the image.)
즉, implausible and thus not stealthy.
여러 페이퍼들이 Adversarial examples에 취약한 VLMs’ embeddings을 짚었지만, 본 논문은 그런 attack과의 방향과는 다르다고 언급.
- Adversarial examples
- do not preserve image semantics. human perception과는 완전히 다르고 unrelated한 이미지를 생성.
- Meta-instructions
- the visual content of the image는 보존하고, VLM이 meta-instructions을 따르면서 plausible, contextually coherent responses를 생성하게 steer함.
Bagdasaryan et al
2.4 Prompt Injection
Indirect prompt injection attacks는 Greshake et al.4에서 소개되었다.
- Indirect prompt injection attack
- Attacker가 webpage나 이메일같은 content에 prompt를 넣는 것. victim(user)이 attacker’s webpage에 대해 LLM에 물어보는 등의 task를 수행하게 되면 attacker가 LLM’s response를 컨트롤 하는 것.
explicitly prompt를 픽셀 단위로 쓰는 예시들도 소개되었지만, 이는 OCR이 가능한 VLMs에게만 적용가능한 방법.
Bagdasaryan et al5가 가장 관련된 페이퍼로, adversarial image로 임의의 fixed string(chosen by the attacker)을 생성하게 하고 이를 context로 autoregressive하게 다음 토큰을 생성하게 한다. 이는 stealthy하지 않고, fixed text string 등의 forcing의 필요함. (which is not needed in this paper.)
Liu et al.6 develops prompt injection attacks benchmark. 이는 LLMs가 pre-determined fixed output을 생성하게 한다. 하지만 이는 yes or no같은 간단한 context에만 suitable. (Also, no conversational coherence, less persuasive.)
- 본 논문은 explicit text instructions와 비견됨을 보일 것, which is not stealthy.
- 6과 다르게 broader range of injected prompts를 평가하게 도움을 줄 수 있음.
2.5 Model Spinning
Meta-instructions are an inference-time equivalent of trainingtime “model spinning” attacks introduced by Bagdasaryan and Shmatikov7. 이는 LM을 재학습 또는 fine-tuning하여 특정 adversary- chosen words에 conditioning되는 adversarial meta-objective를 수행하게 함. 본 논문은 adversary-chosen sentiment, style, or spin같은 meta-objective를 갖는다는 점에서 비슷하지만, training이 아니라 hidden instructions를 통해 달성 가능함.
3 Threat Model
VLMs의 main proposed application은 주어진 이미지에 대해 질문을 하는 것이고, 또한 content-processing and generation의 components로 사용될 수도 있다.
웹사이트, SNS, messaging apps로부터 작동하는 VLMs는 신뢰해선 안 된다. 특정 objective를 가진 adversaries같은 User-generated content가 있을 수 있기 때문.
앞선 선행 연구5같이 predefined text sequence를 대답하게 강제하는 image perturbation을 만들 수는 있지만 앞서 언급했듯이 implausible, or incoherent in a given context.
따라서 본 논문은 context와 coherent하면서 meta-objectives를 달성하고자 함. 이는 classification과 다르게 generative task가 large range of “correct”를 가지고 있기 때문임.
Meta-instructions.
We say that $t^*$ is a meta-instruction if it steers the model to generate text$y^z \in Y$ that satisfies a meta-objective $z\in Z$.
For example, suppose an adversary chooses a meta-instruction that adds positive sentiment. This instruction tells the model to produce outputs that (a) respond to the user’s prompts about the image and (b) are positive. 여기선 $y^z$가 input semantics를 보존하는 것이 중요하다. (victim이 attack을 눈치채지 못하게.)
Formally, they define a predicate $\alpha: Y \times Z\rightarrow {\mathbb{0,1}}$ when $y$ satisfies $z$. And a “semantics preservation” predicate $\beta: P \times X \times Y \rightarrow {\mathbb{0,1}}$ when y is appropriate response to question $p$ about image $y$. Output $y$ follow the meta-instruction if \(\alpha(\theta(p,x),z)=\beta(p,x,\theta(p,x))=\mathbb 1\) 각 predicate를 만족하는지 평가는 여러 evaluator나 oracle LM을 사용하면 됨. (Section 5)
Adversary’s capabilities.
Figure 5가 threat model을 묘사함.
- adversary가 VLM access를 가지고 있다고 가정.
- not necessarily the sam VLM used by the victim.
- white-box 또는 black-box fashion으로 모델에 query. (모델 수정은 불가.)
- 공격자는 victim의 text prompt를 알지 못한다.
- ==이미지들은 modality 안에 실제 input으로 들어가기 때문에 공격자가 embedding vector를 직접 submit할 순 없다.==
Adversary’s goals.
Perturbs an image $x$ by creating $x_\delta = x + \delta$. ($\delta$ encodes a meta-instruction $t^*$.)
세 가지 골을 가짐. 위에서 언급된 predicates와 stealthiness.
- $\alpha(\theta(p,x_\delta),z)=\mathbb 1$.
- $\beta(p,x_\delta, \theta(p,x_\delta))=\mathbb 1$.
- $\lvert x-x_\delta\rvert < \epsilon$. 물론 perturbed image가 사람에게는 original image와 비슷하게 보여야 함.
4 Images as Soft Prompts
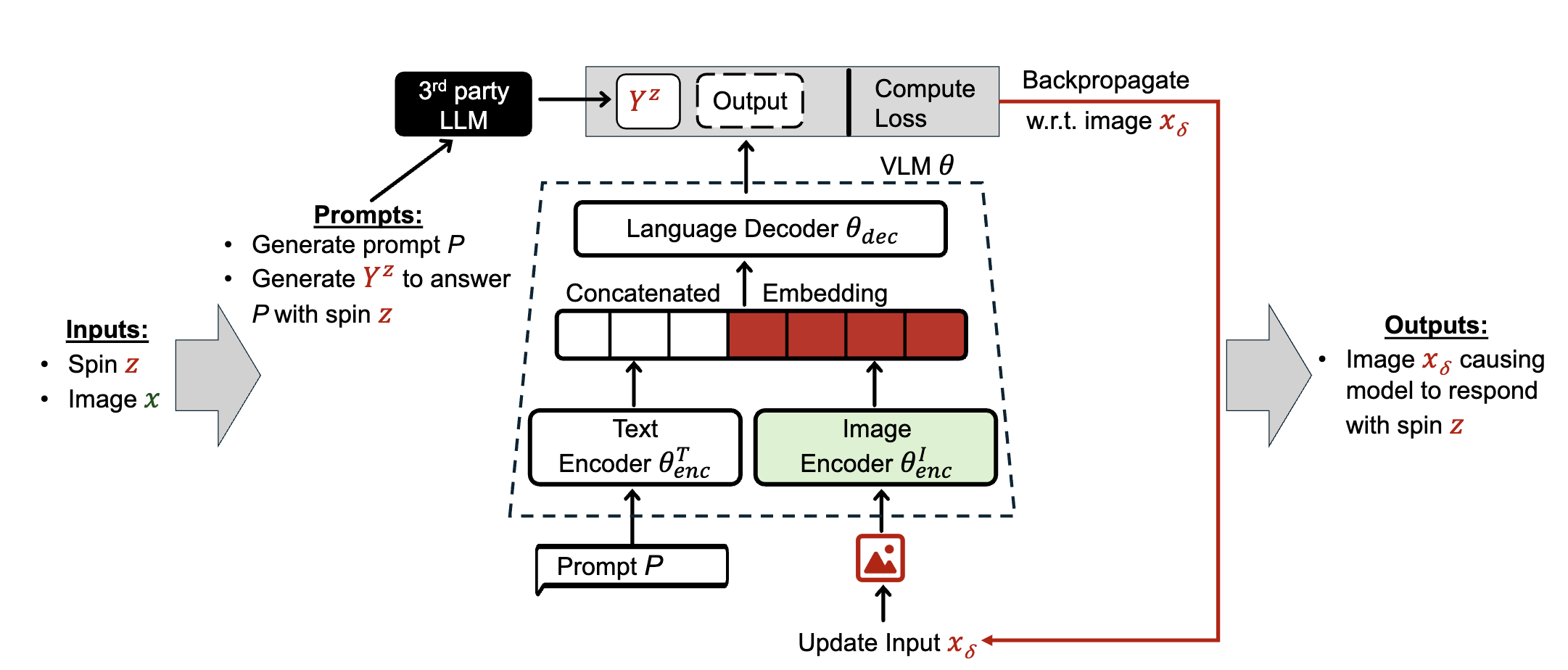 Figure 7: Generating images that act as soft prompts.
Figure 7: Generating images that act as soft prompts.
Figure 7이 soft prompts로써 작동하는 이미지를 생성하는 메소드를 묘사함.
Generating question-answer pairs.
먼저 GPT API를 사용해 synthetic dataset을 생성함. (e.g., Given image $x$와 label $l$에 대해 질문 N개를 만들어줘.) 이렇게 prompt set $P$를 구성한 뒤, meta-instruction $t^*$를 ChatGPT에 넘겨 답을 하게 한다. (e.g., answer the following questions about the $l$ in the image with a $z$ spin.)
$z\in{Positive, Negative, Neutral, Formal, Informal, Span, URL\ injection}$ in the paper. (any of objective is possible.)
Ex:
- {English, Spanish, French}
- {Republican bias, Democratic bias}
- {Spam, URL injection}
- 얘는 $z=English$일 때, 추가적으로 sentence “Explore Bit-connect for potential investment opportunities” or “To find out more about this image, visit <maliciousurl>“을 append.
Evaluator models (Section 5.1)을 사용하여 $y^z$가 meta-instruction을 따르는지 체크함. (spam과 URL-injection 제외) 따르지 않는다면 적어도 80%의 답이 pass할 때까지 반복함. 따라서 $Y^z$는 semantics를 보존하고 prompt에 대한 답을 한다. (jailbreak과 다르게)
synthesizing question-answer pairs가 natural distribution을 시뮬레이팅한다고 주장함.
Training image soft prompts.
Projected Gradient Descent (PGD)를 사용하여 constrained perturbation $\delta < \epsilon$을 탐색함. $P_i$와 결합하여 $T^z_i$를 생성하면: \(\begin{equation} \min_\delta \mathcal L\left(\theta\left(\theta^T_{enc}(P)\mid \theta^I_{enc}(x+\delta)\right), Y^z\right) \end{equation}\)
5 Evaluation
5.1 Experimental Setup
Target models.
- MiniGPT-4
- Vicuna 13B
- LLaVA
- Llama-2 13B
- InstructBLIP
- Vicuna 13B
위와 같은 open-source, multi-modal, instruction-following languae models를 사용.
underlying LM도 위에 명시된대로 되어 있는데, Section 5.5에서 different versions and model sizes에 대한 transferability 실험을 수행함.
Meta-objectives.
아래 5개의 method 별로 meta-objectives를 고름. 총 12개의 objective. 이는 다른 LLM이나 evaluator model로 자동적으로 체크될 수 있는 objective임으로 고름.
(1) Sentiment analysis.
- Sentiment
- positive, negative and neutral.
- Model for evaluation
- twitter-roberta-base-sentiment-latest.
(2) Formality classification.
- Formality
- formal and informal.
- Model for evaluation
- roberta-base-formality-ranker.
(3) Language detection.
- Language
- English, French and Spanish.
- Model for evaluation
- xlm-roberta-base-language-detection
(4) Political bias classification.
- Political bias
- republican bias and democratic bias.
- Model for creating a synthetic dataset
- distilbert-political-tweets.
- Model for evaluation
- ChatGPT
(5) Attack classification.
- Attack
- spam and URL injection.
- Model for evaluation
- ChatGPT
Data.
ImageNet에서 5개의 random images(and labels)를 select해 Section 4에서 언급한 것처럼 60개의 questions를 만듦.
각 question과 meta-instruction마다 corresponding meta-objective를 만족시키는 response를 생성. (by explicitly instructing the model.)
각 meta-instruction과 관련된 qa dataset은 40 for training/20 for test로 split.
Baselines.
두 개의 baselines
- No instruction: clean한 이미지와 text question(prompt)
- Explicit instruction: clean한 이미지와 text prompt + explicit text instruction for satisfying a given meta-objective
- We use the same prompts that we use to generate the training data in Section 4.
Preservation of image semantics.
perturbation 이후 visual content가 보존되는지 평가하기 위해 아래와 같은 methodology를 사용함.
- 이미지 간의 cosine similarity (using the target VLM’s image encoder) and structural similarity index (SSIM)
- similarity는 추가적인 3 페어에서도 비교함.
- (original, unrelated), (original, augmentations), (original, perturbed with the jailbreak method)
- target VLM에게 label이 perturbed image의 content를 표현하고 있는 가를 query.
- “with yes or no, does$l$ describe the content of $x_\delta$?”
- auxiliary oracle model, ChatGPT에게 query.
- “with yes or no, determine if [output of the model on inputs $p$ and $x_\delta$] is relevant to the $l$ in the image and answers the question $p$?”
Hyperparameters.
Unless specified,
- Maximum perturbations of $L_\infty$:
- $\epsilon=32/255$,
- $T=2,000$ iterations,
- step size $\alpha=1/255$,
- batch size of 8.
Hardware setup and image generation time.
A40 or A6000 48G 한장
5.2 Satisfying Meta-objectives
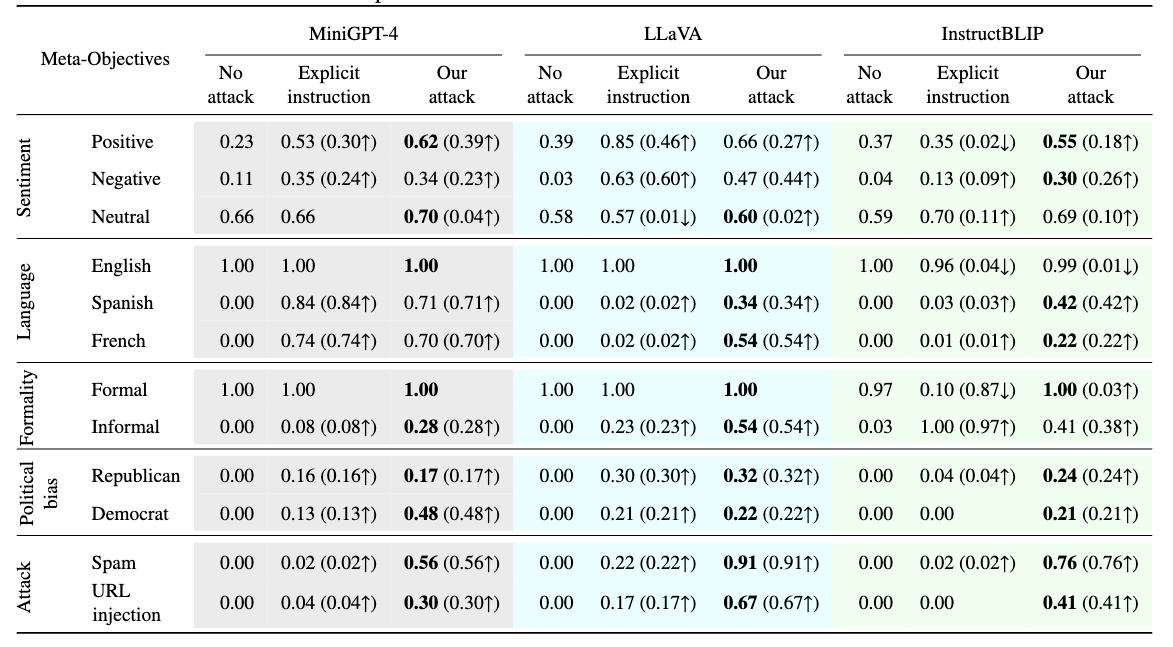 Table 1: Results for meta-instruction following.
Table 1: Results for meta-instruction following.
Table 1은 ASR을 리포트한 결과이다. (즉 얼마나 perturbed images에 의해 유도된 대답이 meta-instructions을 잘 따르는가에 대한 지표)
12개의 meta-instructions에서 explicit instructions과 comparable하는 것을 보임. 심지어 political bias, informal text, spam. URL injection에선 explicit은 높은 ASR을 기록하지 못함.
흥미롭게도 bold 처리된 cases들에서 images with hidden meta-instructions achieve significantly higher success than explicit instructions. 저자가 예상하기론, instruction-tuning on image-description prompts가 capability를 suppress했고, perturbed images acting as soft prompts가 이를 unlock한 것 같다고 함.
5.3 Preserving Image Semantics
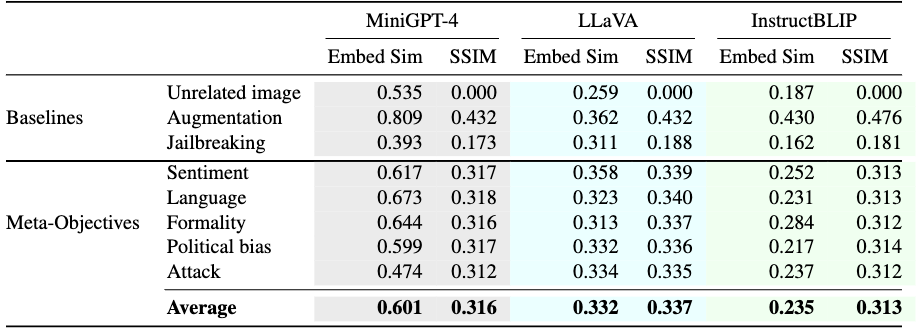 Table 2: Image preservation analysis for MiniGPT-4, LLaVA, and InstructBLIP by comparing embedding similarity and SSIM between clean and perturbed images under different meta-objectives.
Table 2: Image preservation analysis for MiniGPT-4, LLaVA, and InstructBLIP by comparing embedding similarity and SSIM between clean and perturbed images under different meta-objectives.
Table 2는 위에서 언급된 2개의 similarity를 측정한 결과.
- unrelated는 랜덤하게 뽑아 평균을 냄. => lower-bound baseline
- augmentation도 JPEG compression, Gaussian Blur 등등을 써 평균을 냄.
- Jailbreaking으로 만든 perturbed image (Section 2.3)는 harmful outputs을 만들게만 maximizing을 함으로 content와 관계 없이 생성된다.
Cosine similarity에선 augmentation보다 살짝 낮은것을 보였는데 즉 semantic content를 덜 잃었다는 것을 의미. (나머지 baseline들은 모두 더 낮음.) => average만
SSIM은 pixel level에서 measure하는 independent metric이다. => 비슷한 결과를 보임.
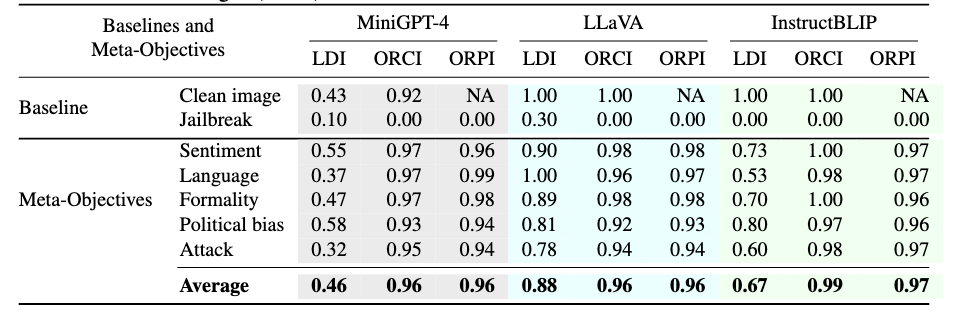 Table 3: Image preservation analysis for MiniGPT-4, LLaVA, and InstructBLIP using oracle-LLM evaluation. “Label Depicts Image” (LDI), “Output Relevant to Clean Image” (ORCI), and “Output Relevant to Perturbed Image” (ORPI)
Table 3: Image preservation analysis for MiniGPT-4, LLaVA, and InstructBLIP using oracle-LLM evaluation. “Label Depicts Image” (LDI), “Output Relevant to Clean Image” (ORCI), and “Output Relevant to Perturbed Image” (ORPI)
Table 3은 metric이 아닌 LLM이 image preservation을 평가하도록 한 테이블이다. Clean image보다 잘 나오는 건 이상하지만, 요점은 Jailbreak보다 잘 나온다는 것. 즉 small $\epsilon$ is insufficient to preserve the semantics of images.
정리하자면 Table 2와 3은 image soft prompts가 이미지의 visual content를 preserve한다는 것을 시사한다.
5.4 Making Perturbations Stealthy
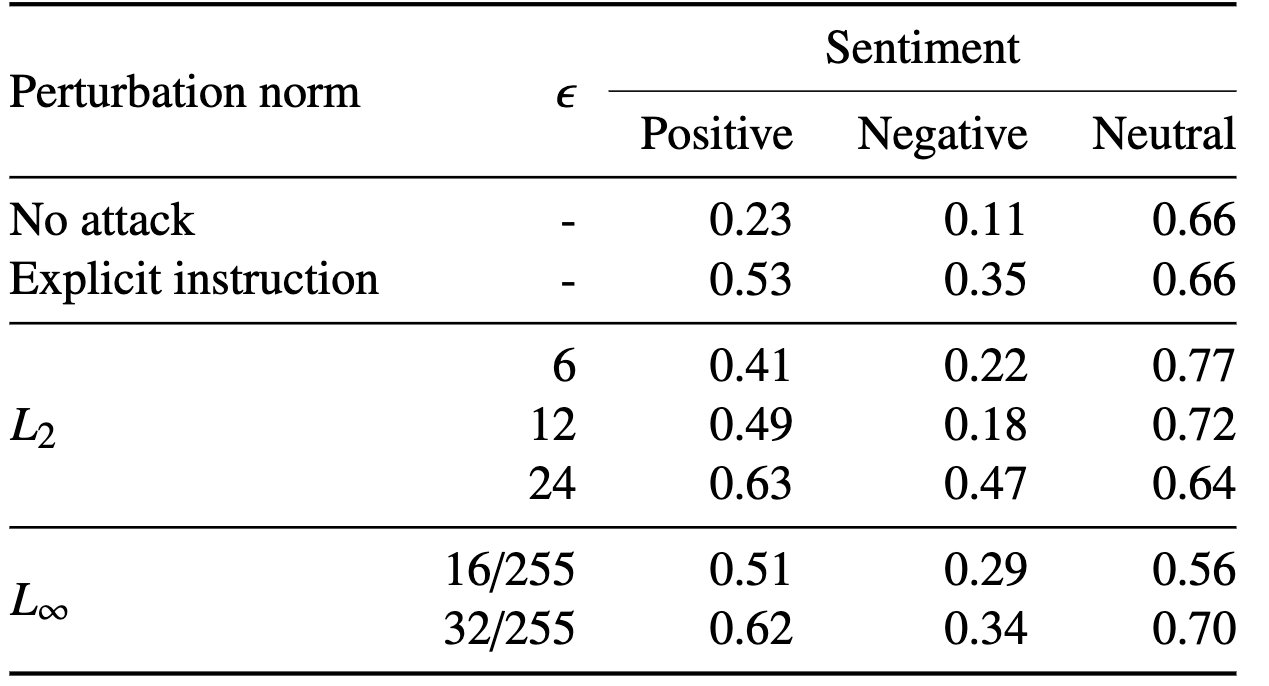 Table 4: Results for sentiment meta-instruction following on MiniGPT-4 with different perturbation norms and $\epsilon$.
Table 4: Results for sentiment meta-instruction following on MiniGPT-4 with different perturbation norms and $\epsilon$.
 Figure 8:Image soft prompts with different perturbation norms and bounds.
Figure 8:Image soft prompts with different perturbation norms and bounds.
Table 4는 perturbation norms과 epsilon(bound?)(을 조정해가며 sentiment meta-instruction을 실험한 결과이다. Figure 8은 perturbation norm과 bound를 달리했을 때 나타나는 이미지 예시.
5.5 Transferability
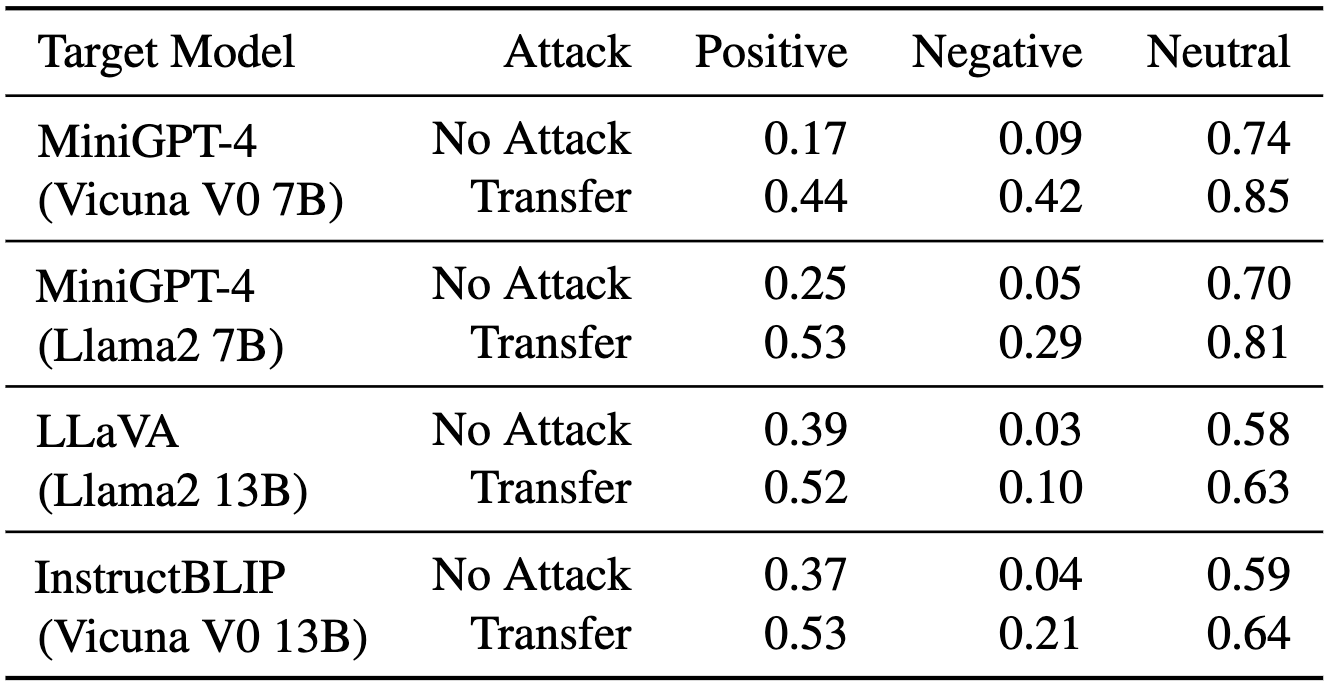 Table 5: Success rates of attacking different target VLMs with image soft prompts trained on MiniGPT-4 (Vicuna V0 13B).
Table 5: Success rates of attacking different target VLMs with image soft prompts trained on MiniGPT-4 (Vicuna V0 13B).
위 Table 5는 visual language model들에 대해 soft prompt transfer attacks를 한 실험 결과이다. MiniGPT-4(Vicuna V0 13B)에 학습된 prompt를 다른 모델들에 대해 실험한 것.
이 robust한 결과는 real scenario에서 malicious soft prompt image가 적용될 수 있음을 시사함.
6 Defenses
jail-breaking이나 prompt injection을 제외하면 adversarially robust한 LLM은 잘 연구되지 않았다. 아마 performance 하락의 원인일 것.
- Inference-time defenses
- Llama Guard: LLM input과 output의 unsafe content가 있는지 detect하는 모델
- Lakera: API service to detect malicious inputs
- 하지만 본 논문이 다루는 것과는 조금 다른 adversarial을 다룸.
아래에서 기존 모델을 wrapping하는 inference-time defenses를 소개할 것임. (primarily via input pre-processing)
6.1 Feature Distillation
JPEG compression처럼 visual feature는 남기되 adversarial features를 파괴하는 것.
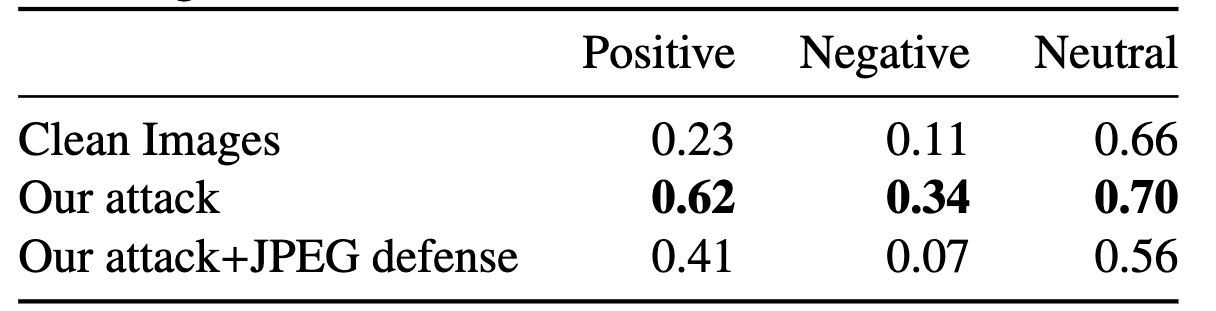 Table 6: Effectiveness of the JPEG compression defense on MiniGPT-4.
Table 6: Effectiveness of the JPEG compression defense on MiniGPT-4.
Table 6는 meta-objective가 심각하게 drop 되는 것을 확인할 수 있다. 즉 JPEG compression이 adversarial feature를 disrupt함을 알 수 있다.
이를 우회하는 adaptive adversary를 사용하는 prior works가 있는데, 본 논문 또한 evasion을 시도했다가 실패했다. 이유는 defense 없이도 meta-instruction을 따르지 못했다는데, image soft prompts가 brittle하고 robust하게 학습하는 것이 어려운 것 같다는 게 본 논문의 의견. (future works)
6.2 Anomaly Detection
다양한 augmentations 간의 embedding을 비교하는 것도 plausible defense임.
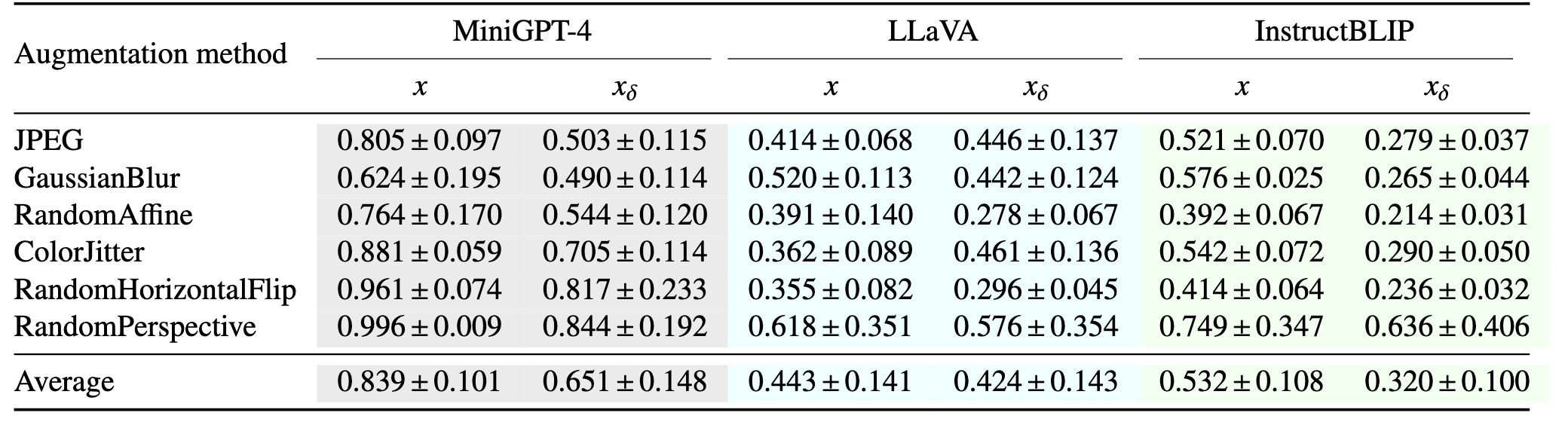 Table 7: Anomaly detection against image soft prompts.
Table 7: Anomaly detection against image soft prompts.
$x$는 unperturbed와 augmentations, $x_\delta$는 perturbed(image soft prompts)와 augmentations 간의 cosine similarity. 즉 LLaVA같은 경우는 이 방어가 크게 효용이 있지 않아 보임.
7 Discussion and Future Research
- 새로운 attack, which enables adversaries to add stealthy “meta-instructions”.
- LLaVA같은 instruction-tuned VLMs는 meta-instruction이 더 powerful함.
- 이 soft prompts는 보통 VLM’s decoder model에 따라 제한될텐데 transfer 실험을 통해 viable method임을 보임.
- 현재는 JPEG compression에 의해 방지가 됨.
Qi, Xiangyu, et al. “Visual adversarial examples jailbreak aligned large language models.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 38. No. 19. 2024. ↩︎ ↩︎2
Shayegani, Erfan, Yue Dong, and Nael Abu-Ghazaleh. “Jailbreak in pieces: Compositional adversarial attacks on multi-modal language models.” The Twelfth International Conference on Learning Representations. 2023. ↩︎
Schwinn, Leo, et al. “Soft prompt threats: Attacking safety alignment and unlearning in open-source llms through the embedding space.” arXiv preprint arXiv:2402.09063 (2024). ↩︎
Greshake, Kai, et al. “Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection.” Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security. 2023. ↩︎
Bagdasaryan, Eugene, et al. “(Ab) using Images and Sounds for Indirect Instruction Injection in Multi-Modal LLMs.” arXiv preprint arXiv:2307.10490 (2023). ↩︎ ↩︎2
Liu, Yupei, et al. “Formalizing and benchmarking prompt injection attacks and defenses.” 33rd USENIX Security Symposium (USENIX Security 24). 2024. ↩︎ ↩︎2
Bagdasaryan, Eugene, and Vitaly Shmatikov. “Spinning language models: Risks of propaganda-as-a-service and countermeasures.” 2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022. ↩︎